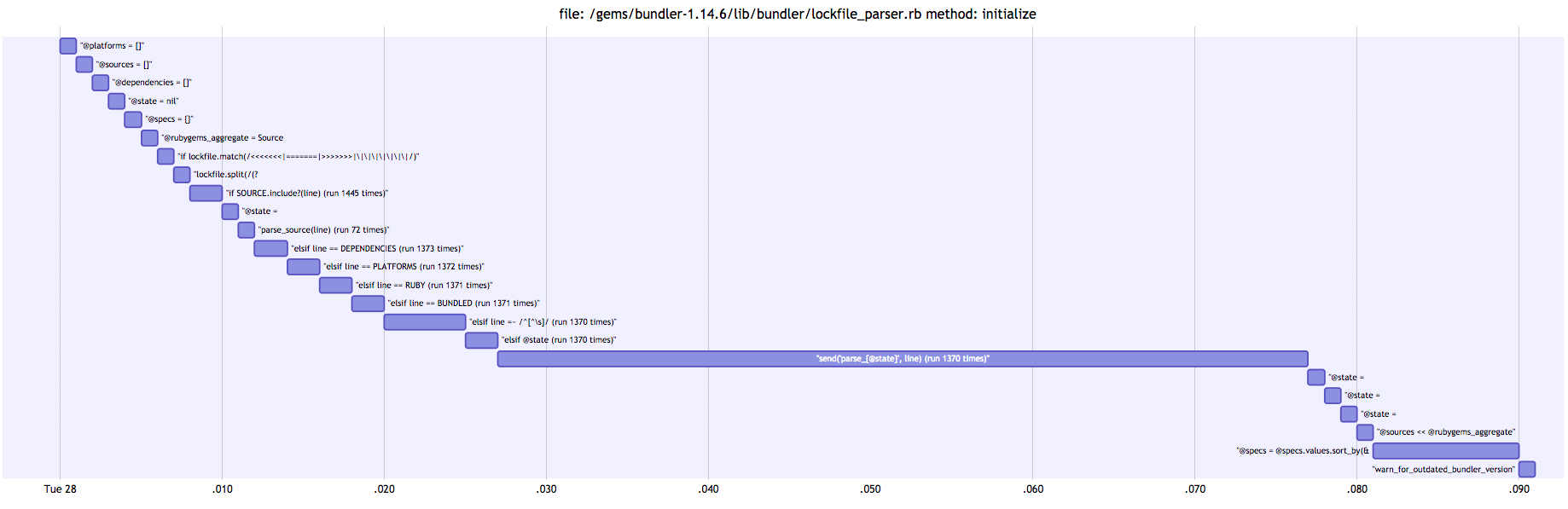
Here, we see that parse_#{@state} is the bulk of the work. This is a dynamic call to parse methods… is any one of them slower than another?
To solve this, I split out the dynamic line into a case statement to see which lines were being called.
elseif @state
+ case @state.to_s
+ when 'source'
+ parse_source(line)
+ when 'dependency'
+ parse_dependency(line)
+ when 'spec'
+ parse_spec(line)
+ when 'platform'
+ parse_platform(line)
+ when 'bundled_with'
+ parse_bundled_with(line)
+ when 'ruby'
+ parse_ruby(line)
+ else
+ send("parse_#{@state}", line)
+ end
- send("parse_#{@state}", line)
end
By the diagram below, we can see the following from our case statement:
| parse_state | number | time | |
|---|---|---|---|
| parse_source | 1131 times | 32ms |
SOURCE did not include line, so it went to the case statement |
| parse_platform | 1 time | 1 ms | - |
| parse_dependency | 237 times | 15 ms | - |
| parse_bundled_with | 1 time | 1 ms | - |
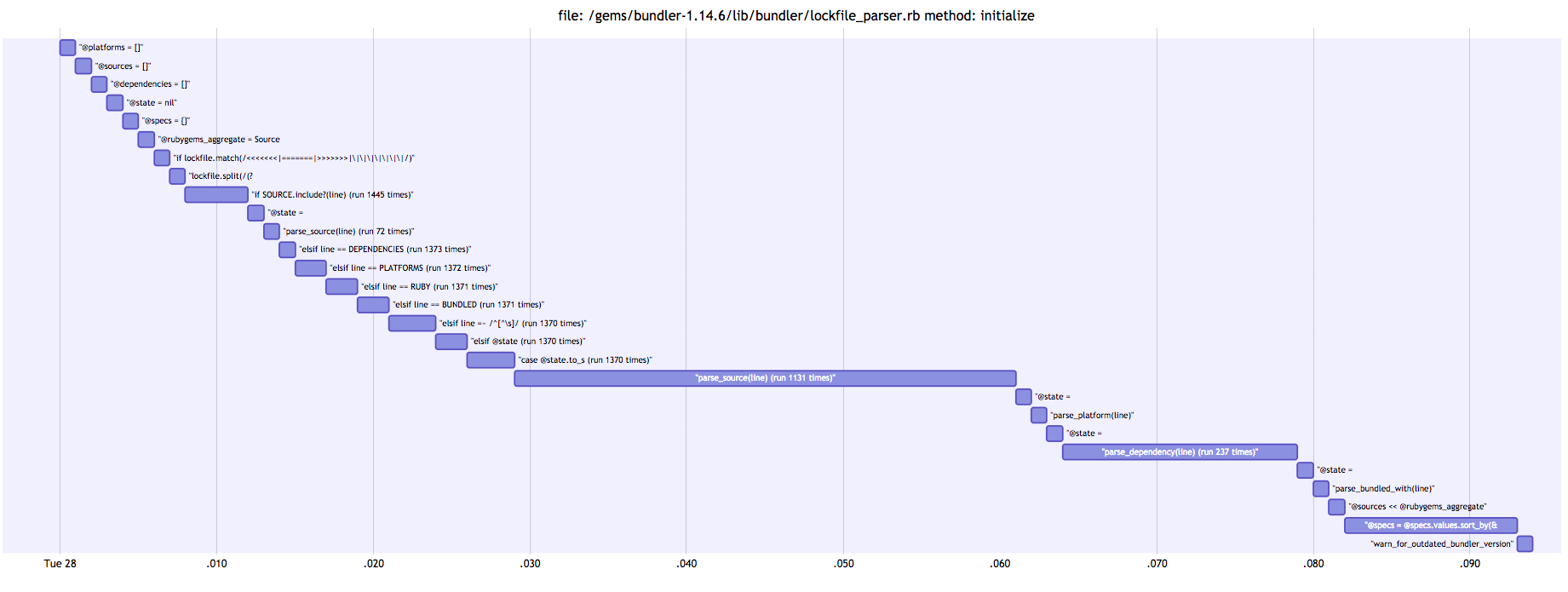
parse_source
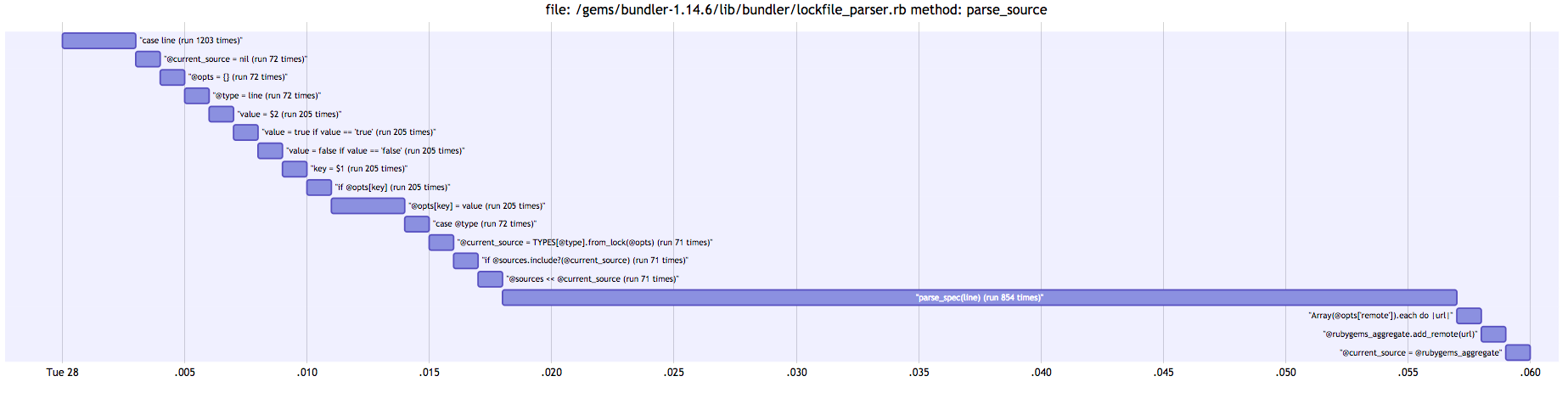
parse_spec is the obvious bulk of this method, so let’s also look there.
parse_spec
The parse spec code looks like so:
def parse_spec(line)
if line =~ NAME_VERSION_4
name = $1
version = $2
platform = $3
version = Gem::Version.new(version)
platform = platform ? Gem::Platform.new(platform) : Gem::Platform::RUBY
@current_spec = LazySpecification.new(name, version, platform)
@current_spec.source = @current_source
# Avoid introducing multiple copies of the same spec (caused by
# duplicate GIT sections)
@specs[@current_spec.identifier] ||= @current_spec
elsif line =~ NAME_VERSION_6
name = $1
version = $2
version = version.split(",").map(&:strip) if version
dep = Gem::Dependency.new(name, version)
@current_spec.dependencies << dep
end
end
It takes about 15-17ms to run all of it. I’d like to see how often each part is called.
- NAME_VERSION_4, called 374 times, took about 7ms
- NAME_VERSION_6, called 480 times, took about 8ms
Which means they take equally as long, but the NAME_VERSION_4 option is slower taking about 0.000044s for each run as opposed to 0.000035s for each run.
So, what is the difference between these two? Well NAME_VERSION_4 is a top level dependency, whereas NAME_VERSION_6 is a sub-dependency, it seems.
NAME VERSION 4 web-console (3.4.0)
NAME VERSION 6 actionview (>= 5.0)
NAME VERSION 6 activemodel (>= 5.0)
NAME VERSION 6 debug_inspector
NAME VERSION 6 railties (>= 5.0)
NAME VERSION 4 webmock (2.3.2)
NAME VERSION 6 addressable (>= 2.3.6)
NAME VERSION 6 crack (>= 0.3.2)
NAME VERSION 6 hashdiff
So what does this actually do? Seems it resolves specifications from the lockfile. The “4 space” (NAME VERSION 4) seems to also load a current spec, which I don’t quite get. Seems we re-assign this class level variable a lot to avoid passing it around.
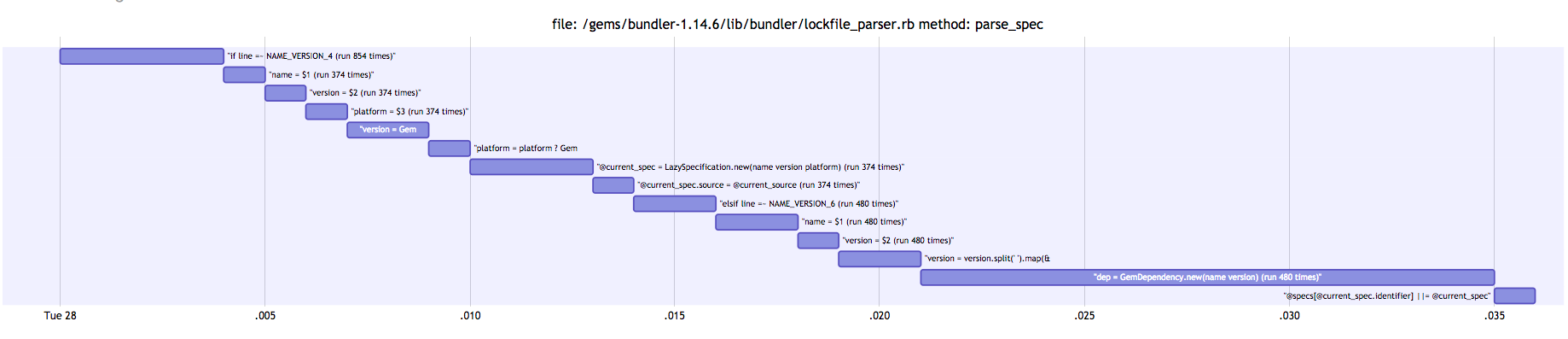
We can see that "dep = GemDependency.new(name version) (run 480 times)" :a1, 0.021, 0.035 takes a chunk of time (14ms with gantt generation, 6ms in reality), otherwise there’s not much bulk here.
So, in the end the reason this file is slower is that it is iterating over many sources and creating Gem::Dependency objects. There is likely something we could do to make LockFileParser faster, but the work likely won’t be worth the time spent.
There isn’t much we can do to make this file faster without caching using marshalling the data or something.